greenlantern (greenlantern)
Make a Private Project
Invite to Bid
Existing Projects

| User Name: | greenlantern |
| Account Type: | Personal Account |
| Date Registered: | 12/09/2025 08:55:09 WIB |
| Last Seen: | 29/09/2025 14:48:04 WIB |
| Provinsi: | |
| Kabupaten: | |
| Website: | |
| Online Hours: | 0.68 |
| Projects Won: | 0 |
| Projects Completed: | 0 |
| Completion Rate | - |
| Projects Arbitrated: | 0 |
| Arbitration Rate | - |
| Current Projects: | 0 |
Ratings & Rankings

0.00/10.00
0 Point
No Ranking
0 Projects
0.00/10.00
0 Point
No Ranking
0 Projects
0.00/10.00
0 Point
No Ranking
0 Sales
0.00/10.00
0 Point
No Ranking
0 Users
Services
No record found.
Products
No record found.
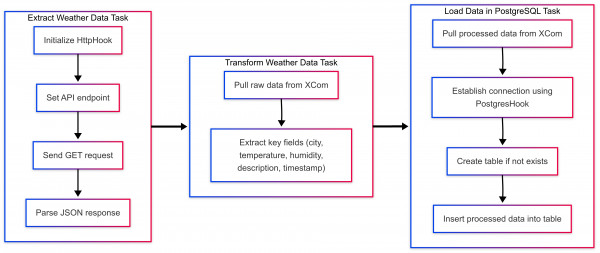
2023: ETL Weather Data Pipeline - This project monitors real-time weather conditions in Jakarta. It fetches data using Airflow’s HTTP integration, processes the response in memory, and then stores key information (e.g., temperature, humidity, weather description, timestamp) into PostgreSQL. This end-to-end pipeline is an excellent demonstration of your skills in data ingestion, processing, and database integration with Airflow.
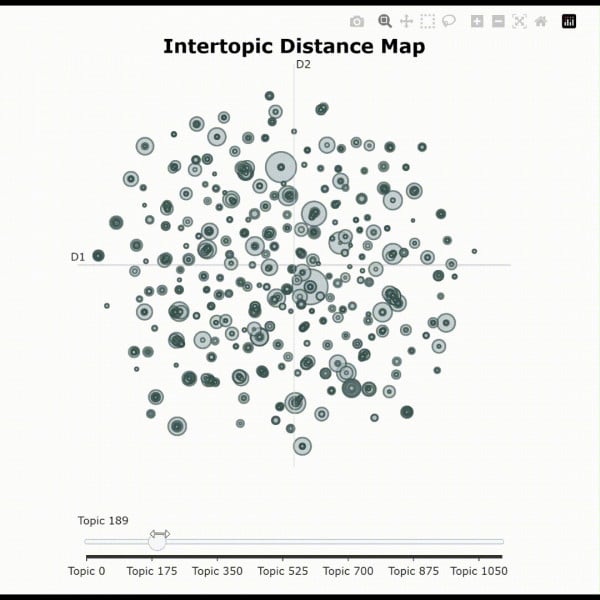
2025: ArXiv Papers Topic Modeling and Research Trend Analysis with BERTopic - This project leverages the arXiv Scientific Research Papers Dataset to uncover hidden topics and analyze research trends over time. Using state-of-the-art NLP techniques, I preprocess the paper summaries and generate contextual embeddings with a pre-trained BERT model. Then, by applying BERTopic for topic modeling, the pipeline extracts latent topics that reveal the underlying themes in scientific research. Finally, by correlating these topics with the published dates, the project visualizes the evolution of research trends over the years. This analysis not only highlights emerging and declining themes but also demonstrates the transformative power of modern NLP in understanding large-scale textual data.
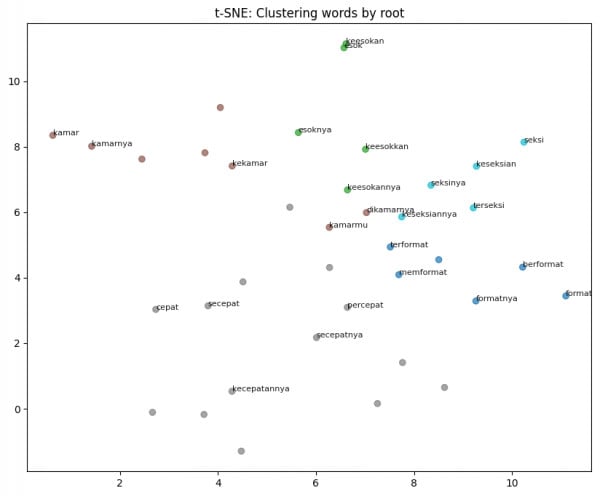
2025: Word Embeddings for Indonesian Academic Corpus - This project focuses on training custom word embedding models for the Indonesian language using a clean, lemmatized, and validated corpus. The main goal is to explore how well these embeddings capture morphological relationships, particularly root-word similarities, and to evaluate their potential for various Natural Language Processing (NLP) applications. The corpus was sourced from the Leipzig Corpora Collection and combined with IndoLeX, a large-scale Indonesian lexical dataset, to ensure linguistic accuracy and domain relevance. The outcome includes a trained Word2Vec model, similarity-based evaluations, and visualized word clusters, providing valuable insights into the structure of Indonesian vocabulary in vector space.
No record found.
No record found.
Anda harus login terlebih dahulu untuk melihat data ini.
You must login first to see this data.
 Loading ...
Loading ...