dm_adhitama (dm_adhitama)
Hire Me
Make a Private Project
Invite to Bid
Existing Projects
Make a Private Project
Invite to Bid
Existing Projects

| User Name: | dm_adhitama |
| Account Type: | Personal Account |
| Date Registered: | 18/11/2016 22:58:37 WIB |
| Last Seen: | 10/01/2026 14:22:54 WIB |
| Provinsi: | Jawa Barat |
| Kabupaten: | Kota Bandung |
| Website: | |
| Online Hours: | 77.51 |
| Projects Won: | 3 |
| Projects Completed: | 3 |
| Completion Rate | 100.00% Excellent |
| Projects Arbitrated: | 0 |
| Arbitration Rate | 0.00% Excellent |
| Current Projects: | 0 |
Ratings & Rankings
As Worker

10.00/10.00
145 Point
#3,322 dari 1,691,050
3 Projects
10.00/10.00
145 Point
#3,322 dari 1,691,050
3 Projects
As Owner

0.00/10.00
0 Point
No Ranking
0 Projects
0.00/10.00
0 Point
No Ranking
0 Projects
As Seller
0.00/10.00
0 Point
No Ranking
0 Sales
0.00/10.00
0 Point
No Ranking
0 Sales
As Affiliate
0.00/10.00
0 Point
No Ranking
0 Users
0.00/10.00
0 Point
No Ranking
0 Users
Services
No record found.
Products
No record found.
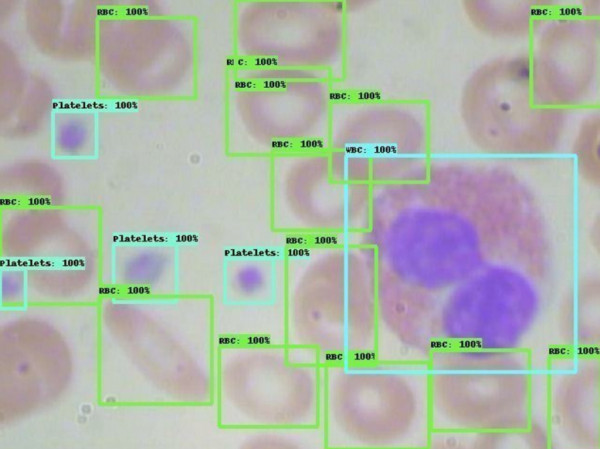
2019: This project proceeded in a straightforward manner. The company I collaborated with provided a dataset comprising blood cell images, encompassing both red and white blood cells. The objective was to train an AI model, specifically an object detection model, to accurately detect and localize both red and white blood cells within the images. The workflow I followed was also straightforward.
(1). I augmented the image dataset and divided it into three subsets: training, validation, and test datasets.
(2). I explored and experimented with various existing object detection models, utilizing different backbone models, using the training and validation datasets.
(3). Finally, I tested the trained models using the test dataset and evaluated the results obtained from each model.

2020: The primary objective of the project is to develop an AI-powered automated visual inspection system tailored for inspecting camshafts, potentially supplementing or substituting human inspectors. Our initial challenge lay in initiating and advancing this novel endeavor. Below, I delineate the progression of our project's development:
(1). Conduct a comprehensive examination of the camshaft to analyze prevalent defects. This includes interviewing human inspectors to understand their inspection methods and the characteristics of detected defects.
(2). Develop the infrastructure necessary for data collection, encompassing considerations such as background setup, camera specifications, lens requirements, object-to-lens distance, lighting arrangements, and more. Additionally, simulate the process of capturing camshaft images within this designated environment.
(3). Acquire defective camshafts and artificially induce defects to facilitate testing. These defects will be intentionally created rather than naturally occurring on the camshaft.
(4). Investigate available AI models suitable for integration into the project. Various AI-based image processing techniques, such as image segmentation, classification, and object detection, were explored extensively. After thorough research, experimentation, and testing, the decision was made to employ an object detection algorithm for this endeavor.
(5). Perform manual annotation of the collected images and apply image augmentation techniques to enrich the dataset. Subsequently, utilize this augmented dataset to train various pre-existing AI models.
(6). Conduct further experiments to refine the models, ultimately selecting the most optimal outcome based on performance metrics.
(7). Concurrently, as my partner develops the backend and frontend systems, I integrate the best-performing model into the system. This model is then deployed onto hardware, some kind of mini-PC namely Jetson, and tested on the pre-established machine with the standardized environment we previously defined.
Outcome:
Since February 2019, when the project commenced, significant progress has been achieved. We successfully developed a system that has been deployed within the automated visual inspection machine. Testing conducted with real, non-artificially defected camshafts has yielded an accuracy rate ranging between 80-90 percent. Furthermore, our system demonstrated the capability to identify up to 5 out of the 6 proposed distinct defect types, marking a notable advancement in our project's objectives.

2020: We designed a cutting-edge auto-parts counter system, integrating object detection, computer vision for object identification, and tracking capabilities. This initiative aimed to supplant the conventional weight-scaling method previously employed for auto-parts counting. The former method's susceptibility to errors due to slight variations in the weight of each produced auto-part necessitated a more precise solution, which our AI-based auto-parts counter system provides. Herein, I outline the progress made in this project up to February 2020.
(1). Due to the visual similarities among the auto-parts, we found it feasible to collect images of the parts from various angles. Camera placement was not extensively considered as the machine environment producing the auto-parts was highly specific, reducing the likelihood of flexible camera placement options.
(2). Upon gathering a selection of these images, we proceeded to annotate the dataset and then train the object-detection model. Given the singular object type and its relatively low complexity, a compact and straightforward model sufficed for our purposes.
(3). Following the model training phase, we integrated additional algorithms for object tracking. These included rule-based and computer vision-based approaches. The object tracker algorithm not only tracked detected objects but also counted them as long as they remained within the camera's field of view.
This project remained at the prototype and proof-of-concept stage throughout my tenure until I departed from the company in February 2020. Despite not being fully implemented at that time, the outcomes attained were highly promising.

2020: The objective of this project is to develop an automated system capable of extracting information from paper documents. These documents consist of both handwritten and computer-generated text, all of which necessitate extraction. This project can be divided into two methods:
(1). Handwritten text extraction. The texts are fortunately situated in highly specific locations. Leveraging this advantage, we manually delineate these areas as regions of interest. Within these defined areas, segmentation is executed to generate overlapped segmented regions, each representing an individual character. Subsequently, a pre-trained AI model is employed to infer the handwritten character images into single characters. Lastly, a rule-based algorithm facilitates the conversion of multiple characters into sentences.
(2). Computer-generated text. For this part, we can readily apply an OCR technique for conversion. Although this technique is robust, it requires further scrutiny of the results. Regrettably, we haven't yet conducted additional experiments in this area. However, our approach for post-processing after the system generates the OCR outputs is well-defined.
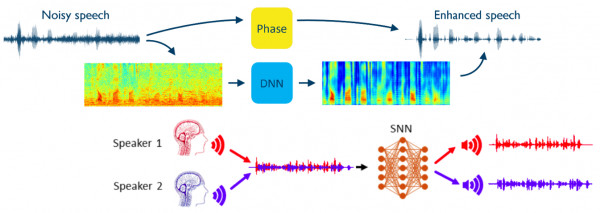
2021: Design a preprocessing system to enhance speech signal before it proceeds to the ASR (automatic speech recognition) models. There are some approaches that I worked on, for instance, noise-removal, dereverberation, and speaker separation for overlapping speaker cases.
(1). Noise removal. Speech audio signals are often disrupted by environmental noise, typically categorized as additive noise, which poses a straightforward challenge. Initially, I employed a predefined signal filter in the noise removal process. However, due to the diverse nature of additive noise types, an alternative approach utilizing AI models was pursued. To facilitate this, an exploration and collection phase of potential additive noises occurring in real-world scenarios was conducted. These noises were then used to augment clean speech audio, enabling the training of AI models with the anticipation that they could effectively differentiate between learned and similar additive noises.
(2). Dereverberation. Reverberation represents another type of noise, characterized as a convolutional noise. Unlike additive noise, defining reverberation is more complex due to the necessity of estimating the impulse response responsible for its occurrence. This task is challenging as it requires the estimation of one or multiple impulse responses. Even with the aid of AI models and extensive training using reverberated data, including their impulse responses, accurately defining reverberation remains difficult.
(3). Speaker separation. Another type of additive noise is overlapped speaker noise, which is generated by human speech unintended for recording. This noise typically exhibits very low energy or amplitude, resulting in a babbling sound that even human ears struggle to percieve. To address this, we must isolate and remove this type of speech separately, requiring the use of AI modeling. Numerous research avenues exist for this approach, although results have been imperfect. Occasionally, the AI model may erroneously remove non-babble speech. Experimentation with this method continued beyond my resignation from the company.
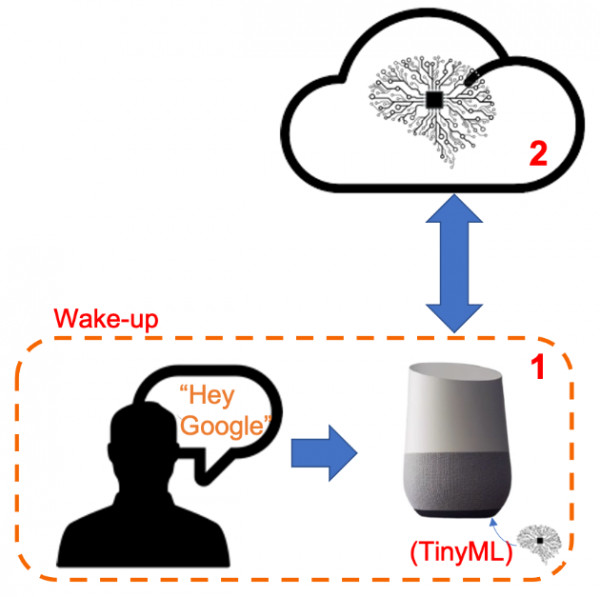
2022: The wake-up word project was launched to streamline certain speech applications. Instead of manually activating an Automatic Speech Recognition (ASR) application with a trigger button, the wake-up word feature allows for activation by specific user commands, such as "Hello system!" or "OK system!". Developing and experimenting with the wake-up word system is relatively straightforward.
(1). The initial step involves defining the specific words or phrases to serve as the wake-up word.
(2). I proceeded to determine the speech features to utilize, opting for features such as Mel-Frequency Cepstral Coefficients (MFCC) and Perceptual Linear Prediction (PLP). By experimenting with these selected features, I aimed to evaluate their performance and determine which one yields superior results.
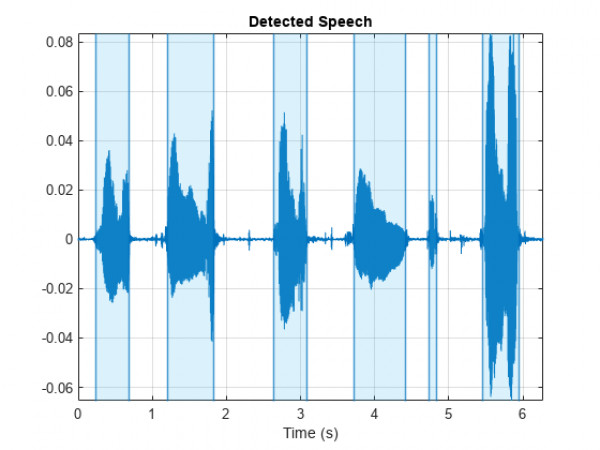
2023: To enhance efficiency and accuracy, a novel approach to Voice Activity Detection (VAD) algorithm design was devised. VAD typically identifies silence segments within speech signal audio. By accurately detecting and localizing these segments, we can effectively segment the entire speech signal. This segmentation is crucial for reducing the computational cost of decoding in the Automatic Speech Recognition (ASR) model.
The entire VAD experiment process relies on digital signal processing algorithms. We deliberately avoided employing deep learning models to circumvent the feature extraction step within the VAD process. By directly applying DSP algorithms, we achieved a notable reduction in computational costs.
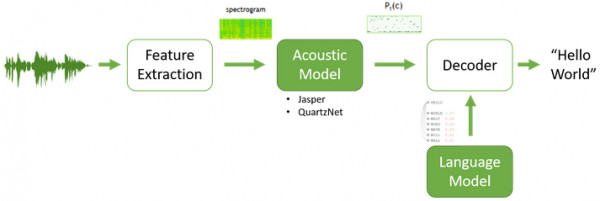
2023: This is a well-established long-term project aimed at maintaining and enhancing the existing Automatic Speech Recognition (ASR) model or potentially developing a new one to yield superior results. My primary focus within this domain is on maintaining and advancing the traditional ASR model, which consists of two key components: an acoustic model (AM) and a language model (LM).
Over time, it became routine to collect new datasets from the client, acquire newly annotated (transcribed) speech audio datasets, prepare the data, and simultaneously train the LM and AM. Subsequently, these trained models were tested to assess their performance.
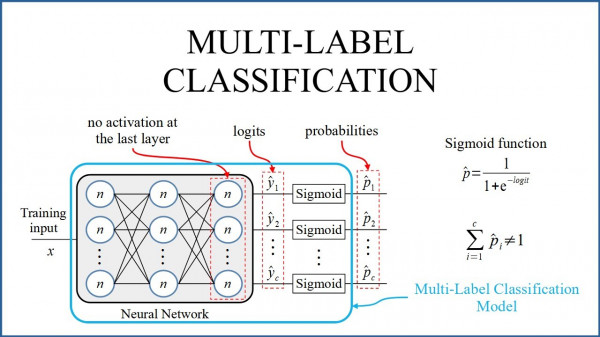
2023: The purpose of this project is to reproduce the SOTA result of FrameExit: Conditional Early Exiting for Efficient Video Recognition paper.
This research utilizes the Holistic Video Understanding (HVU) dataset primarily intended to facilitate action recognition experiments. However, it has been discovered that this dataset can also support experiments in multi-label video classification.
In this project, we encountered challenges reproducing the State-of-the-Art (SOTA) results due to the unavailability of algorithm code and unclear explanations hindering our reimplementation efforts. However, through leveraging existing models and making certain modifications, we ultimately surpassed the SOTA results. The State-of-the-Art mean Average Precision (mAP) stood at 49.2%, whereas our achieved mAP reached 49.28%
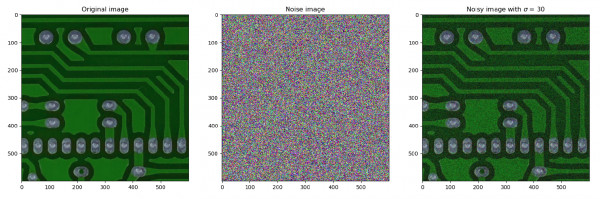
2023: This project involved replicating a State-of-the-Art (SOTA) paper concerning defect classification in PCB images and enhancing the results through fine-tuning existing models.
The PCB dataset contained six defect types, necessitating dataset augmentation due to its limited number of images. Augmentation involved random cropping, alongside the addition of Gaussian noise with sigma values of 0, 30, and 60, as per the baseline paper's recommendations.
For further insight, I have included detailed results in this portfolio.
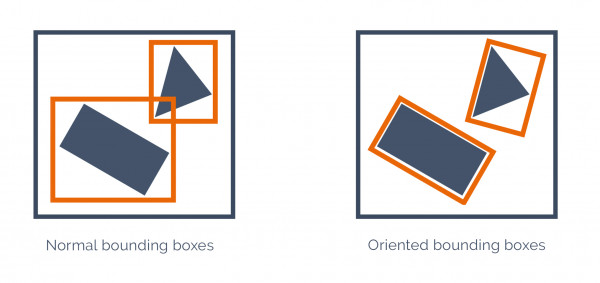
2023: This project, initiated by a company, aims to detect defects in LED installations on PCBs. LED defects are determined by the angle of installation; a non-defective LED is installed without tilting, while a tilted LED requires the AI model to generate an oriented bounding box, including its angle.
Due to the private nature of the dataset, no baseline results were available. Consequently, I established a new baseline and subsequently endeavored to enhance it by adapting the baseline model.
The primary challenge lay in modifying the existing model to generate oriented bounding boxes, as the original model only produced normal bounding boxes with two annotation points.
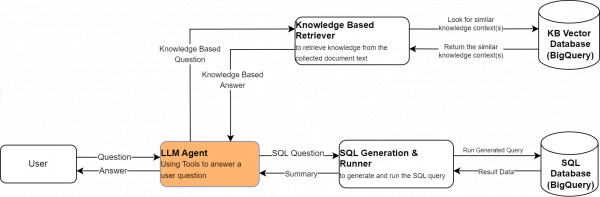
2024: This project is currently in progress, focusing on the research and development of an AI-based chat application utilizing Language Model (LLM) technology.
The aim is to create a chat AI capable of answering questions pertaining to specific hospital group information, drawing from both database records and uploaded knowledge sources.
Various approaches have been explored, including LLM chaining and agent-based methods, along with prompt engineering techniques. Additionally, flow design has been implemented to distinguish database-related inquiries from general knowledge inquiries. Efforts have also been made to fine-tune existing LLMs.
Continued development aims to enhance processing speed while maintaining high accuracy in responses.
Project Ending: Completed Rating:
Sampai ketemu di lain projects

JogjaMultimedia 01/05/2024 00:48:34 WIB Image Prosessing Dengan YOLO
Project Ending: Completed Rating:
Komunikatif, profesional, dan sangat membantu. Semoga bisa bekerjasama lagi pak, terima kasih

relacilia 22/04/2024 22:15:05 WIB Mencari Mentor terkait Deep Learning
Project Ending: Completed Rating:
F
Aplikasi Validasi Relawan Pemilu
* Monitoring Pendukung
Fungsi ini untuk melihat akumulasi jumlah pendukung dan Memetahkan berdasarkan Umur,Jenis Kelamin guna untuk persiapan Logistik
* Monitoring Relawan
Fungsi ini untuk melihat total jumlah Relawan dan Memetahkan berdasarkan Umur,Jenis Kelamin guna untuk persiapan Logistik
* Progres Pemenangan
Untuk melihat progres pemenangan berdasarkan target kemenangan dengan capain suara yang di targetkan
* Management Relawan
Fitur ini untuk menambahkan Relawan atau Timses sesuai dengan tupoksi yang di inginkan kandidat
* Management Logistik
Fungsi ini untuk melihat laporan keunagan kandidat dan juga mendeteksi kemana saja arah logistiknya
* Indikator Kinerja Relawan
Kinerja relawan dapat diukur agar terlihat produktivitas pergerakannya
* Kerahasian Data
Setiap relawan hanya bisa melihat data yang merekan input,( Tidak bisa melihat data relawan lain
* Scan KTP (Auto input)
Konversi data dapat langsung dilakukan hanya dengan foto KTP dan data akan secara otomatis terinput
* Dapat Digunakan Offline
Dapat digunakan secara maksimal di wilayah yang masih terbatas jaringan Internet.
* DTDC ( Door to Door Campaign)
Fitur DTDC berfungsi untuk memudahkan relawan untuk mengimput data calon pemilih yang siap mendukung kandidat berdasarkan wilayah relawan
* AGENDA
Sistem management strategi yang terstruktur sehingga relawan mudah mendapatkan informasi penting dari kandidat
* LOGISTIK
Fitur logistik membantu anda dalam management keuangan dan barang, dimana sistem ini memberikan data relawan yang telah mendapatkan logistik, kemudian pelaporan relawan dalam menyalurkan logistikgan, saya disuruh untuk memberikan RAB anggaran, hitungkan lah per fitur harga dan berapa lama pengerjaan normal, dari - flow belum ada
- deskripsi belum ada
- ui belum ada
- jenis ? mobile / web
- jumlah pengguna ?
- testing ?
- server budget ?
- budget development ?
- apakah ada thirdparty yg terhubung ?
- maintenance?
- admin menu nya apa ?
- mobile menu mya apa ?
- domain ?
- apakah beli putus ?
- apakah ada biaya maintenance?

qbsdevs 20/04/2024 06:27:12 WIB membantu saya mengerjana project fine tuning roberta model LLM
Total Rows: 3 ‐ Showing Page 1 of 1
No record found.
Anda harus login terlebih dahulu untuk melihat data ini.
You must login first to see this data.
 Loading ...
Loading ...